

Five Laws of Modeling 99% of Marketers Violate

Listen to the audio version here
If you want ROI, stop "statistical modeling" (or driver analysis) and start causal AI. It's not obvious when data science recommendations are wrong. Plausibility is not a good test, nor is "trying the recommendation" a reliable test. If you don't know the truth, you can't see the failure. Because of this tragedy, billions of dollars are wasted around the world on bogus analysis. Even if your modeling partner has a Ph.D. and eloquently assures you that his work is state of the art, after reading this article, you will know better - even if you are "just" a marketer. And you will know how to do it better: Let's go.
“If you don’t know the truth, you can not see the failure.”
In marketing, insights teams use modeling for many applications. They analyze customer satisfaction drivers, brand drivers, marketing mix modeling, and more. Simply because you cannot simply ask a consumer why and how they choose a product and then expect an unbiased answer, modeling is expected to find the link between perception and customer behavior. It is also expected to find the link between marketing spend per channel and sales results.
This "link" has a name in science: its beautiful name is "causality". The most important question in business is what to do to achieve an outcome. Business questions are fundamentally causal questions.
If this is the cause, why not use a modeling method that tries to conform to the laws of causal inference?
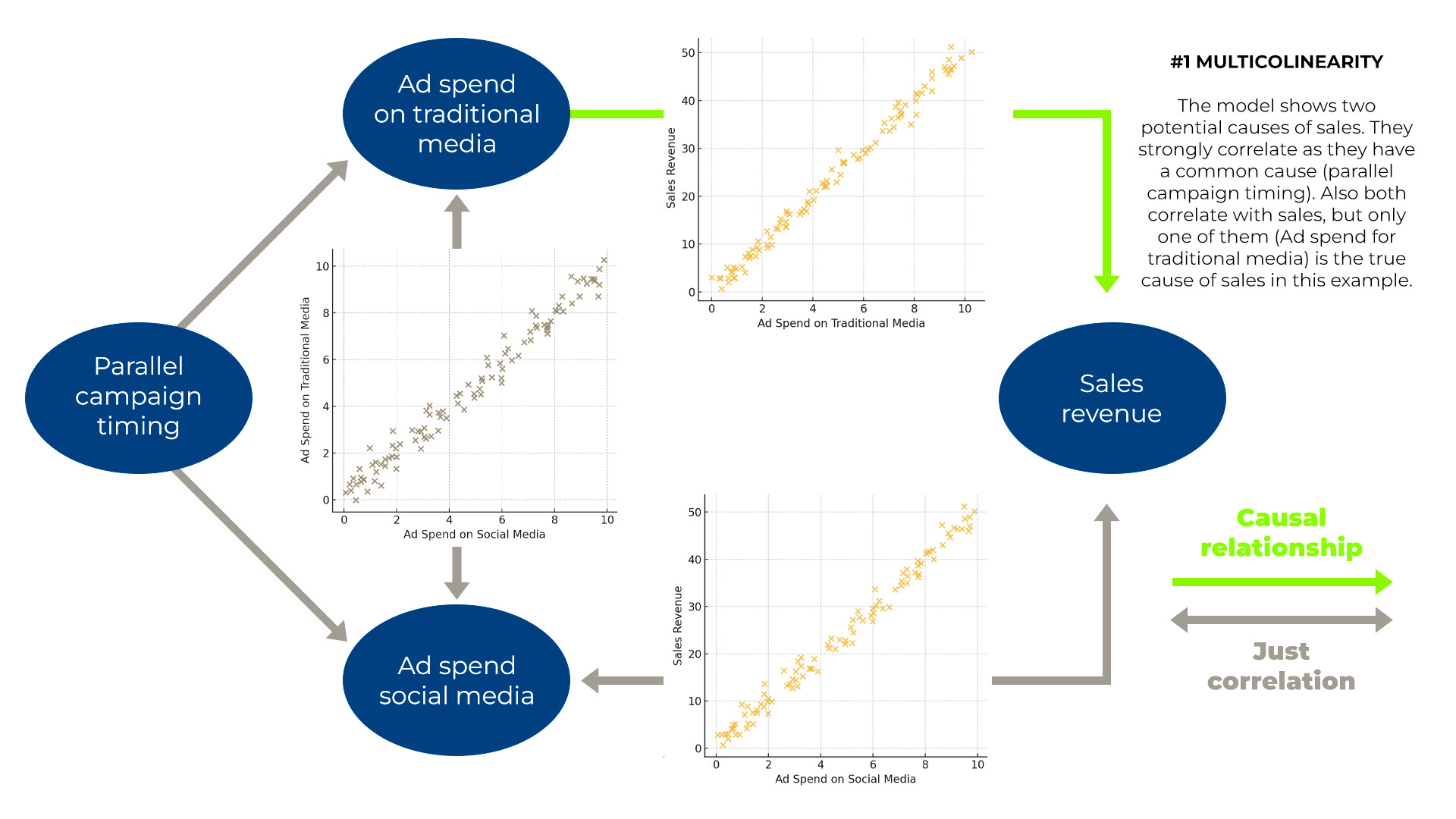
Law #1 – Multicolinearity is a fog that makes it hard to see causal truth
The image below shows a real data simulation. Ad spend data per day or week often correlates simply because the media plan has defined them to play together. Traditional media spend is high when social ad spend is high and vice versa in this example.
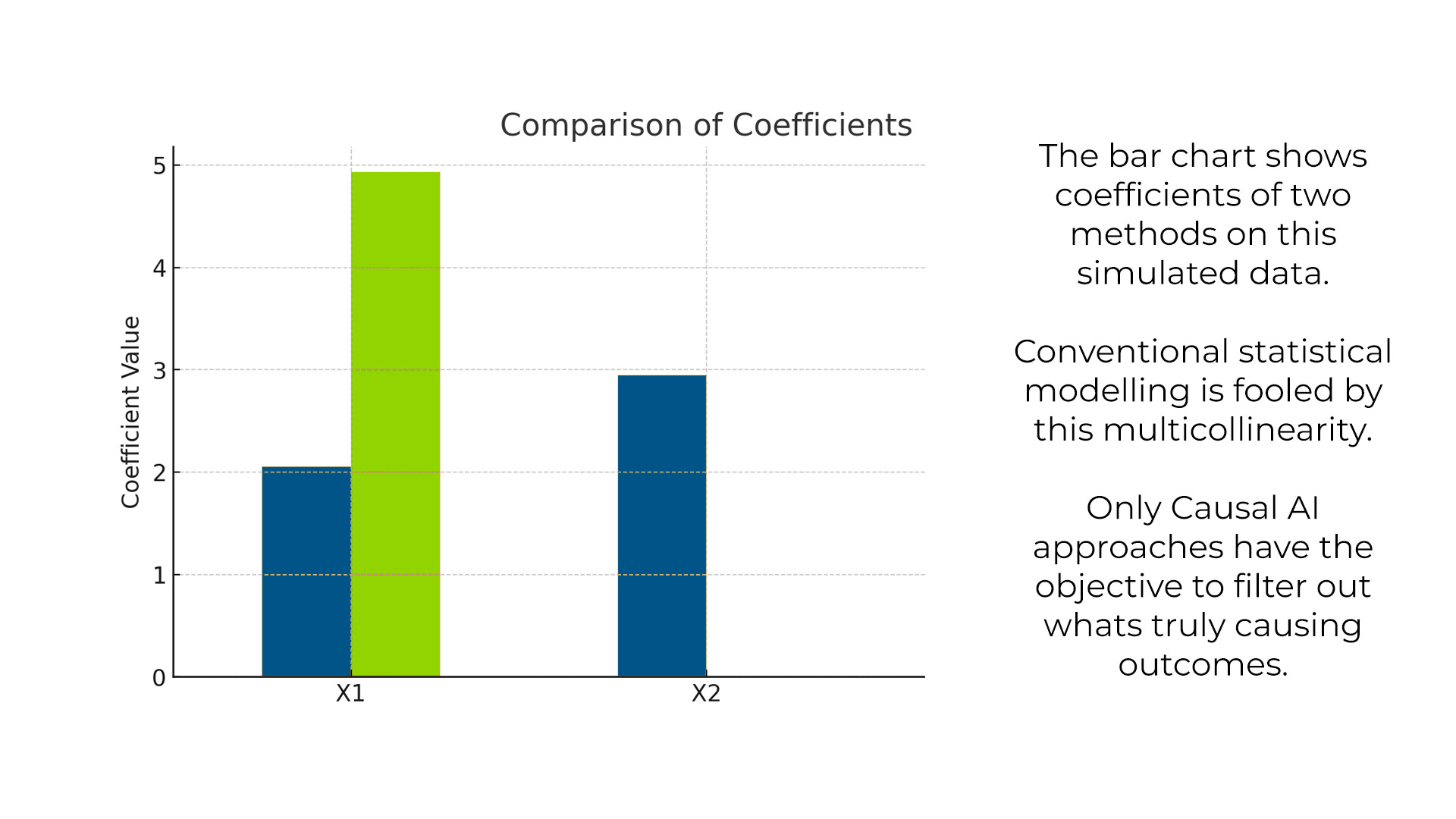
Imagine that only one of the channels - traditional media in this example - is driving sales (green causal link). Because of this causal link, sales will correlate with traditional media spend. But because traditional media is also correlated with social spend, social ad spend will also correlate with sales. The higher these correlations, the more co-correlated variables in the model, and the more unusual (non-linear, non-gaussian) the reality is, the harder the modeling will be able to distinguish between causal and correlative relationships.
CAUSAL AI uses specialized algorithms to see through the fog and distinguish between causation and correlation.
If you use methods that do not address Law #1, your attribution of effects will be unreliable or even wrong. For example, in an application like risk prediction (accepting loan customers), this regularly leads to discrimination. The race or gender associated variable correlates with salary, while the letter is the cause, not the race or gender.
Law #2 – Representativity biases lead to mirages
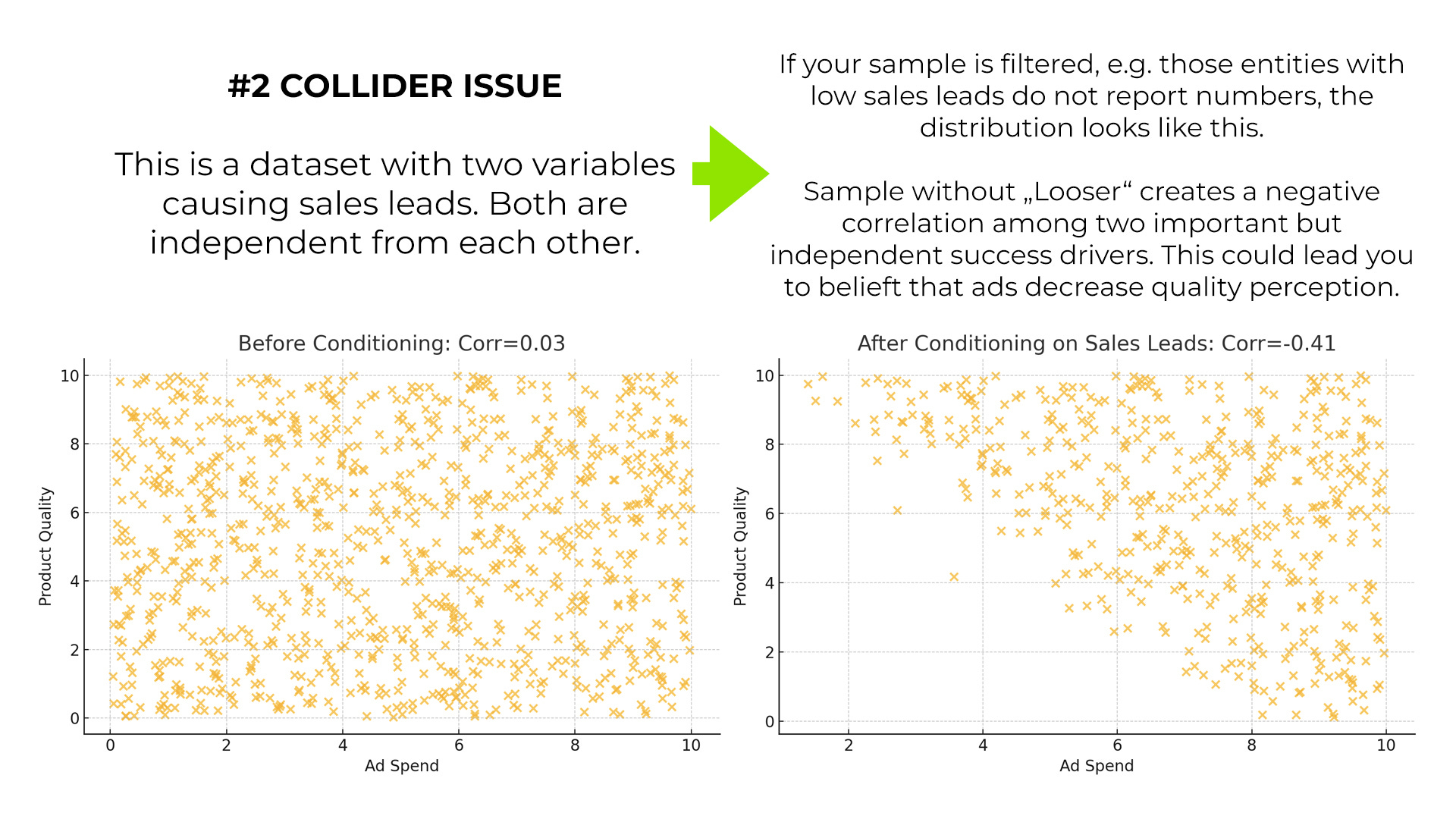
Imagine, for a particular case, that ad spending causes sales. Further suppose product quality causes sales. Let us assume that both causes are independent in this case. Now we build a dataset on product launches. Imagine we include one record per month for each product for its first two years on the market.
What happens is that 95% of the products do not survive this period. In fact, most are only on the market for a few months. As a result, successful products with high sales are heavily overrepresented in the sample.
For visualization purposes, you can see on the left the true sample with each product having a point and on the right the biased sample with missing points for looser products. In our example, it is not binary, but the point is the same: if you correlate both variables, you see that they are negatively "associated" - even though they are not. In other words, over-representing successful cases, or filtering out cases that depend on the outcome, can lead to strange correlations.
In the end, you may conclude that advertising reduces the perception of product quality and is therefore counterproductive.
Why is this important? We all find it plausible to study winners to understand what drives success. Bookstores are full of books that take this idea to every possible level.
When we consulted with a Bundesliga club, we found that they were analyzing how and where goals were scored, not realizing that it was the missed shots that were needed to understand success. The same thing happens in business all the time.
“We all find it plausible to study winners. But without studying loosers it is meaningless”
Causal (not casual) thinkers know this and avoid filtering the sample whenever possible. But sampling bias can be subtle and unexpected or unknown. This is where the inclusion of context information in the Causal AI model can serve as substitute information and represent the filter information. With this inclusion, the correlation is inferred to this context information and not to the otherwise considered variables.
In data science jargon, this effect and law is also known as the COLLIDER effect.
Satisfaction and NPS studies, for example, suffer from the overrepresentation of very happy AND very dissatisfied customers. Since the moderate customers are underrepresented, this leads to a correlation between different topics (reasons for satisfaction or loyalty). This multicollinearity leads to the challenge of Law #1, for which I already talked about the countermeasures.
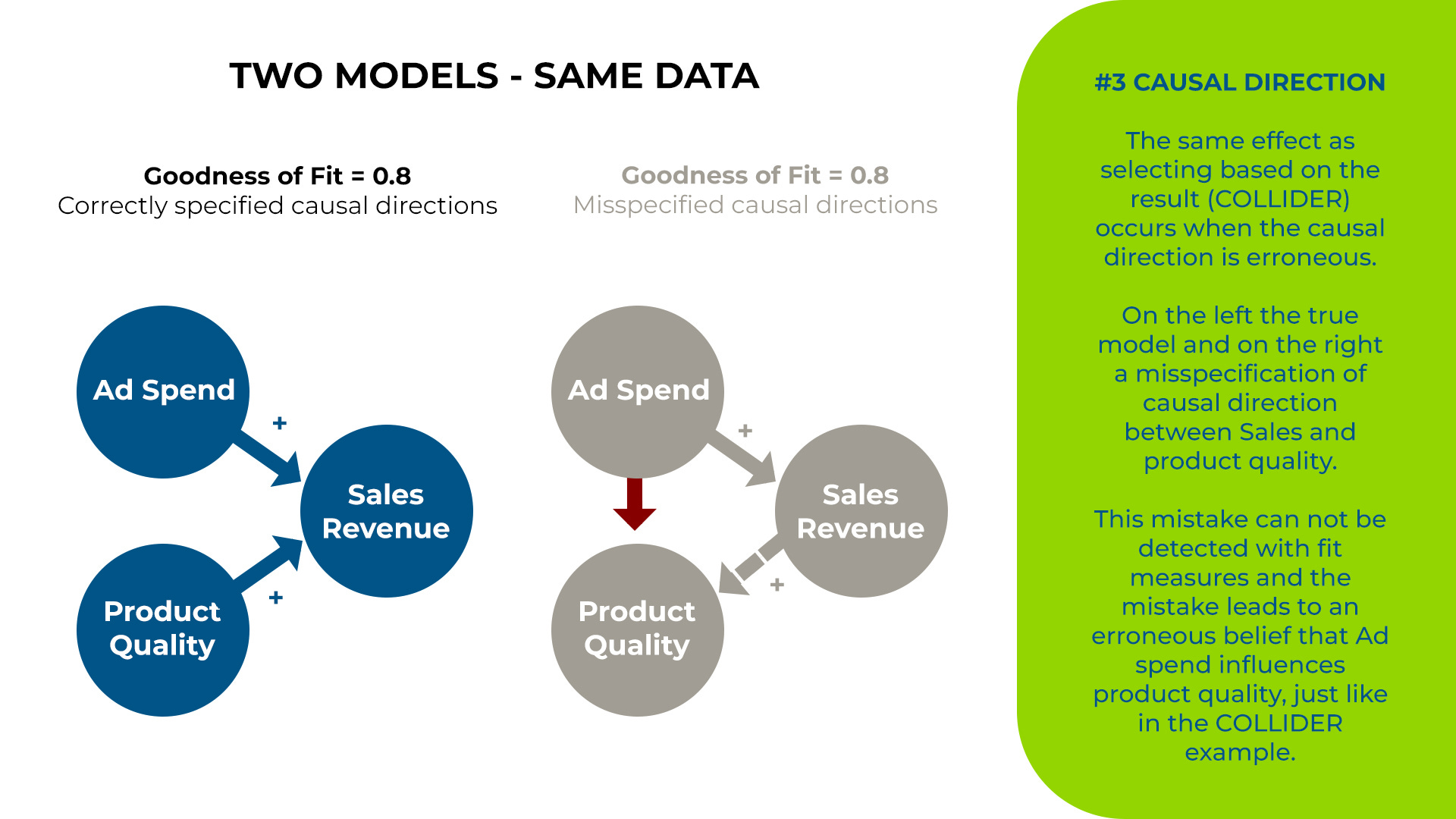
Law #3 – Choosing Causal Direction Changes Results
Consider the model in the figure below. The left model and the right model differ in the assumed causal directions. If you run a model on the same data, you will get the same fit, but completely different results. Model fit tells you nothing about truth. The common belief, however, is to throw all the data into a model and then see if it fits. As you can see, it's a naive approach to modeling.
“Model fit does not tell you anything about truth.”
Causal inference requires a choice (or assumption) about causal directions. This choice can be tested/validated (e.g., conditional independence test or additive noise modeling), but such a test will also rely on other assumptions. This means that expert judgment about causal direction is always required. If you're lucky, you can validate it (this can happen well for small models), but don't bet on it.
In marketing science, we typically know enough to judge causal direction. Bring your team up to speed in marketing science (not just market research) and you are equipped to build proper models.
The problem is that most people in research agencies are often not trained in marketing. They are psychologists or sociologists. You don't need to have a marketing degree, but if you don't understand that customer insights require marketing know-how, you're in the wrong place.
At SUPRA, we have fed our LLM with our marketing know-how that has flown into hundreds of marketing models. As a result, the SUPRA Causal AI system will suggest a causal direction that is ready to go in 90% of causes.
Law #4 – External confounders can flip results from true to false without a trace
Everyone knows the problem of seasonality. Many products are bought at the end of the year. At the same time, companies invest in more advertising because demand is higher at that time. As a result, ad spending correlates with sales because we spend more when we KNOW we will sell more anyway. The figure below shows the simplified underlying causal phenomenon.
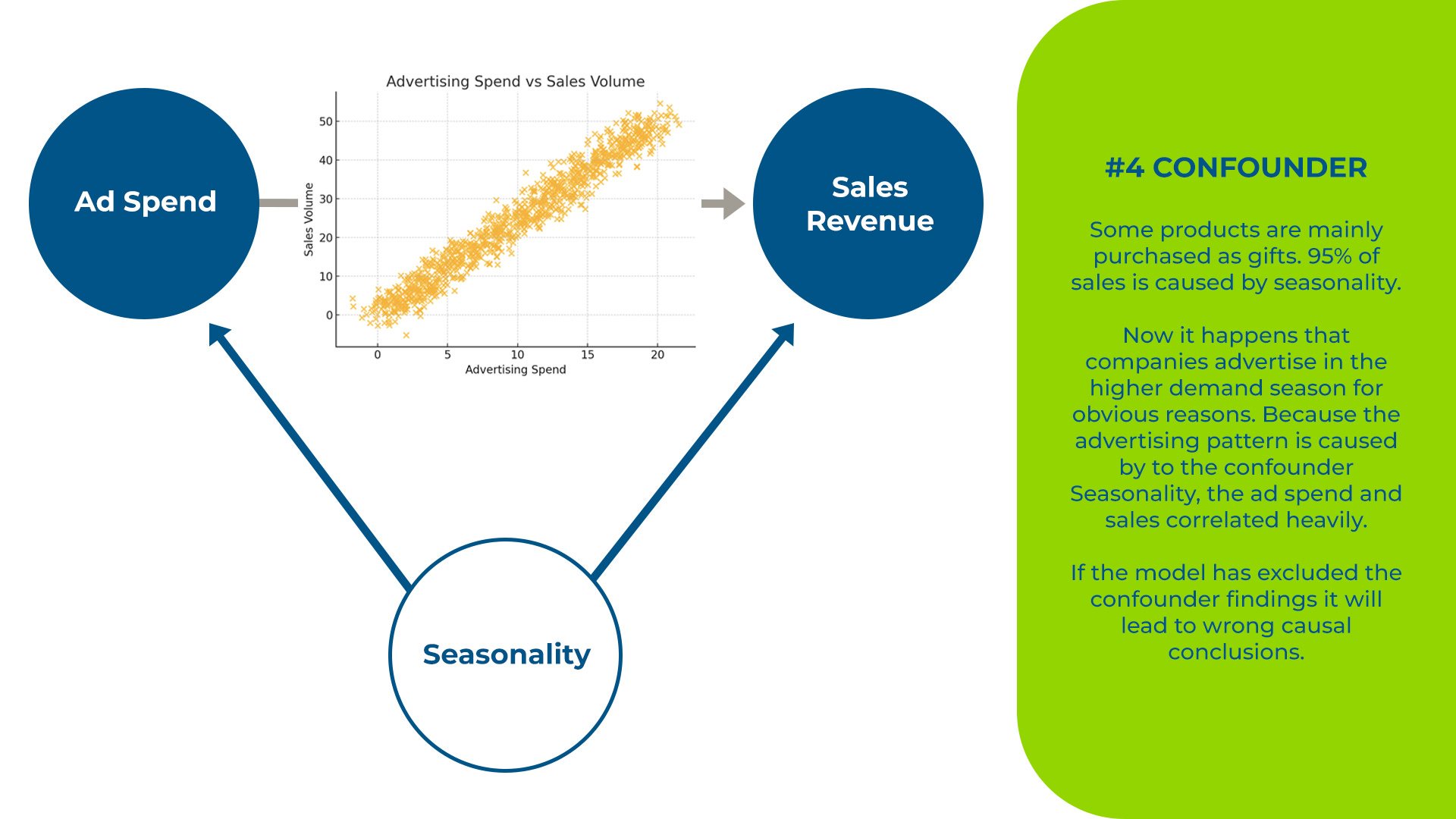
That's obvious, right? But most confounders are not so obvious.
We once found that NPS was negatively correlated with the following year's revenue of a person. It turned out that certain customer segments had higher expectations and therefore lower NPS per default. But they also bought more and churned less per default.
Below is a graph showing engagement (Y) with a particular incentive (X). The correlation is negative. But when you look at the data by segment, it is positive.
The segment may be a confounder. That is why we at Supra are notorious for looking at contextual information to make a model holistic and to integrate potential external confounders.

Why is this important? The default mode of modeling in business and science is very different. It only includes variables that you are sure are important (confirmatory approach). If the model does not show good significance numbers, more and more variables are eliminated until the parameters become significant. This process is known as "p-hacking". It leads to models that are "very significant" but "very wrong".
“Traditional model trimming results in models that are "very significant" but "very wrong”.”
This process makes the models incorrect by increasing the risk that external confounders will lead to incorrect causal insights.
Law #5 – Nonlinearities (and interactions) can flip results from true to false without a trace, too
We simulated the model shown in the figure below. The true causal relationship between ad spending and customer engagement in this model is non-linear. This is how the data was generated. Too much ad exposure can annoy customers.
Now you can model the data with a linear model. It assumes that each causal relationship can be described by a single parameter. This is how most modeling is done today. Data scientists claim that models may not be completely linear, but they can be approximated well enough with a linear model.
Our simulation below proves that this is a lazy and dangerous assumption. Data scientists use these assumptions because testing for nonlinearities on, say, a hundred variables is a lot of work, and when it comes to interaction effects, this is truly prohibitive as the work scales exponentially.
The simulation proves that linear assumptions on nonlinear problems not only inaccurately model the nonlinear relationship but can also interfere with the correct estimation of ALL OTHER causal variables.
This is a largely underestimated problem in modeling and even in causal AI.

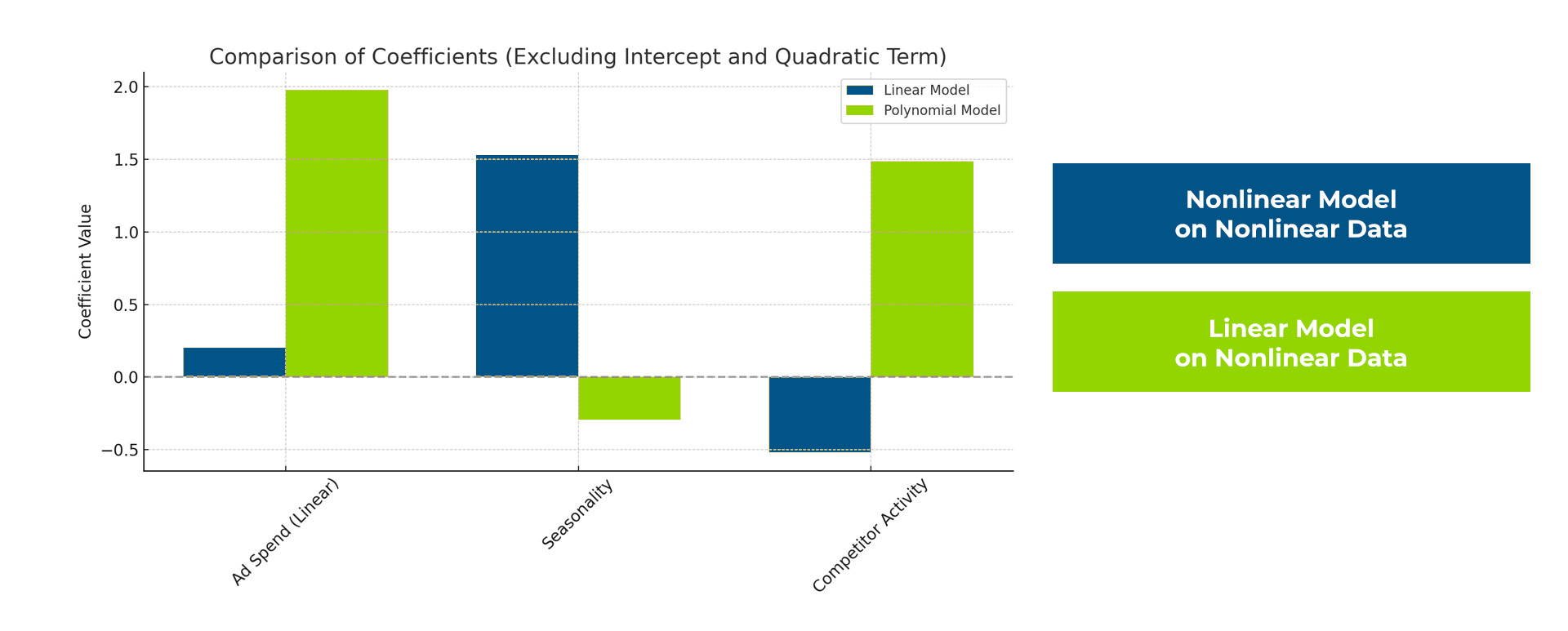
With SUPRA Causal AI all these challenges are a thing of the past. Nonlinearities and any interactions are modeled "as they are" without the need to name them.
10x Impact by Complying to the Five Laws
Where is the impact? Isn't it obvious? It is as universal a lever as a good education. Hard to quantify, but definitely a game changer. Can you be successful without it? Sure, with great talent, intuition, street smarts and hard work. But if you add education, or in this case, causal truth about highly complex matters: next level.
I have described dozens of applications in my latest book "Think Causal Not Casual" and more in other 10xInsights articles.
Modeling should be used in all areas of marketing insights, whether it is product, service, brand, touchpoints, marketing mix, or advertising optimization. All five laws are typically violated in traditional modeling. Do you wonder why marketers are often unconvinced? Perhaps their intuition tells them that "something is wrong”.
When you read about how traditional modeling violates all these laws of proper (causal) modeling, you might feel: How can generations of smart statisticians and data scientists be so wrong?
Actually, it's not that black and white. Really experienced data scientists know about these laws and implicitly or explicitly try to follow them. "Handcrafted" models optimized by true experts are indeed often useful. But in today's project environment, it is simply not economical to spend months tweaking and iterating models. Instead, we find ordinary statisticians building models or DIY tools used by marketers. And these can be quite dangerous.
The advent of Causal AI changes that and brings a new level of impactful insights to birth.
What leverage would you expect if you better understood which ad channels have the highest ROI, which brand archetype attracts customers, which product feature drives adoption, which creative tactic drives ad impact, which touchpoints drive the marketing funnel, which market segments are most receptive, which customer experience moments have the highest impact, and so on.
When you get fundamentally better answers to these and other questions...
THIS... is how you create 10x impact with insights.